
From the monthly archives: septembre 2011
 On a (presque) oublié la vocation première de Louis Ferdinand Destouches plus connu sous son nom de plume L.F.Céline… un médecin occasionnel devenu homme de lettres au style révolutionnaire. L’un des premiers à faire incorporer le langage de la rue dans des romans lucides, engagés ou nihilistes. Il a su jouer sur des sonorités, il a ajouté la musique dans le roman traditionnel. L’un de ses tous premiers écrits est disponible aux éditions Gallimard collection Imaginaire : Semmelweis (préface inédite de Philippe Sollers), 1999, 128 p. Cette édition comporte une bibliographie sur Semmelweis établie par Jean-Pierre Dauphin et Henri Godard, ainsi que différents textes parus après la soutenance de la thèse de Louis Ferdinand en 1924. Dès l’écriture de sa thèse LFC affiche son style : sonore, provoquant, sans concession. Cette thèse est d’ores et déjà un objet littéraire à part entière (lors de sa soutenance Céline à 30 ans). Le sujet de cette biographie analytique : « la vie et l’oeuvre de Philippe Ignace Semmelweis (1818-1865) » est singulier à plusieurs niveaux : l’histoire d’un confrère (de LFC) « scientifique » face à une conviction dont il n’arrive pas à tirer une démonstration, l’histoire d’une opposition au conservatisme, un homme fort de ses déductions dont les paires rejettent les conséquences (un Galilée de la médecine). Dans sa thèse Céline décrit la valse macabre de la fièvre puerpérale qui passe des salles de dissection aux salles d’accouchements. Semmelweis convaincu – sans arriver à le démontrer formellement- que le vecteur de ces infections étaient les mains souillées des étudiants qui passaient de salles mortuaires aux salles d’accouchement. Céline peint un Semmelweis comme un obstétricien maniaque, déterminé, persuadé d’être dans le vrai quand, après observation, il essaie de persuader ses confrères de se laver les mains au chlorure de chaux -une idée de l’aseptie avant l’invention du mot microbe (par Charles Sédillot en 1878, 13 ans après la mort de Semmelweis). Une biographie tragique où l’obscurantisme est un des éléments poussant Semmelweis vers la folie. Quelques décennies plus tard, Louis Pasteur connaîtra un autre sort.
On a (presque) oublié la vocation première de Louis Ferdinand Destouches plus connu sous son nom de plume L.F.Céline… un médecin occasionnel devenu homme de lettres au style révolutionnaire. L’un des premiers à faire incorporer le langage de la rue dans des romans lucides, engagés ou nihilistes. Il a su jouer sur des sonorités, il a ajouté la musique dans le roman traditionnel. L’un de ses tous premiers écrits est disponible aux éditions Gallimard collection Imaginaire : Semmelweis (préface inédite de Philippe Sollers), 1999, 128 p. Cette édition comporte une bibliographie sur Semmelweis établie par Jean-Pierre Dauphin et Henri Godard, ainsi que différents textes parus après la soutenance de la thèse de Louis Ferdinand en 1924. Dès l’écriture de sa thèse LFC affiche son style : sonore, provoquant, sans concession. Cette thèse est d’ores et déjà un objet littéraire à part entière (lors de sa soutenance Céline à 30 ans). Le sujet de cette biographie analytique : « la vie et l’oeuvre de Philippe Ignace Semmelweis (1818-1865) » est singulier à plusieurs niveaux : l’histoire d’un confrère (de LFC) « scientifique » face à une conviction dont il n’arrive pas à tirer une démonstration, l’histoire d’une opposition au conservatisme, un homme fort de ses déductions dont les paires rejettent les conséquences (un Galilée de la médecine). Dans sa thèse Céline décrit la valse macabre de la fièvre puerpérale qui passe des salles de dissection aux salles d’accouchements. Semmelweis convaincu – sans arriver à le démontrer formellement- que le vecteur de ces infections étaient les mains souillées des étudiants qui passaient de salles mortuaires aux salles d’accouchement. Céline peint un Semmelweis comme un obstétricien maniaque, déterminé, persuadé d’être dans le vrai quand, après observation, il essaie de persuader ses confrères de se laver les mains au chlorure de chaux -une idée de l’aseptie avant l’invention du mot microbe (par Charles Sédillot en 1878, 13 ans après la mort de Semmelweis). Une biographie tragique où l’obscurantisme est un des éléments poussant Semmelweis vers la folie. Quelques décennies plus tard, Louis Pasteur connaîtra un autre sort.
 Il est de nos jours surprenant et presque déstabilisant, de lire une thèse de médecine, de moins de 80 pages qui constitue un objet littéraire abouti, une observation scientifique et humaine, argumentée et subtile. Seul contre tous, Semmelweis a maintenu sa position. Quant à lui, Céline par la voix de Bardamu -médecin anti-héros du Voyage au bout de la nuit- donne une définition de la médecine libérale : « larbin pour les riches, voleur pour les pauvres. »
Il est de nos jours surprenant et presque déstabilisant, de lire une thèse de médecine, de moins de 80 pages qui constitue un objet littéraire abouti, une observation scientifique et humaine, argumentée et subtile. Seul contre tous, Semmelweis a maintenu sa position. Quant à lui, Céline par la voix de Bardamu -médecin anti-héros du Voyage au bout de la nuit- donne une définition de la médecine libérale : « larbin pour les riches, voleur pour les pauvres. »

HEALTH MAP : WHO is watching you !
( -L’OMS vous regarde !-)
Encore une application liée à Google Map.
Grossièrement, à l’aide de :
contributions « volontaires » (par l’intermédiaire d’une application sur smart phone : Outbreak Near Me – « épidémie près de chez moi », cf. capture d’écran ci-contre) vous pouvez ainsi « dénoncer » votre voisin qui a la grippe (à vous la charge du diagnostic…), et le cas sera (peut-être) référencé, associé à une date et une géolocalisation puis reporté sur la planisphère) – simple efficace un tantinet intrusif.
en scrutant de manière automatisée à large échelle le contenu des réseaux sociaux, les flux de nouvelles locales, les dépêches, les flux d’informations informelles (SMS, Twitter…), et en appliquant une « analyse sémantique » automatisée du contenu. Cet outil est capable, en se référant à un dictionnaire des localités et des maladies, d’attribuer un cas relaté d’une maladie donnée à une géolocalisation que l’on souhaite la plus précise possible. Un outil basé sur le principe de détection sémantique contextuelle (cf. bibliographie en accès gratuit dans PubMed)
L’objectif ? Suivre en temps proche l’évolution d’une pandémie, observer avec un temps d’avance l’arrivée de la grippe saisonnière par exemple… avec plus de 2300 lieux, 1100 « maladies » dans le dictionnaire de référence… la vigie automatisée a du travail !
 Le projet peut paraître séduisant. Il constitue un fantastique système de surveillance (un de plus, dirons les septiques) pour l’OMS. Même si l’information est bruitée (suite à un mauvais diagnostic, une information journalistique n’est pas une information scientifique) ou comporte des erreurs dans le couple d’attribution maladie / lieu, l’outil a misé sur la vélocité dans son aptitude à remonter de l’information que l’on souhaite la plus pertinente possible. Il est en perpétuelle amélioration. Sur Health Map, vous pouvez suivre jour après jour, tels des boutons de varicelles, des spots en relation avec votre agent infectieux favori s’illuminent sur la carte mondiale. Outre l’outil (une application de la fouille de texte, encore une) le site internet est très ergonomique et utile notamment pour sa section : « The Disease Daily« . Une critique possible : le continent africain fait les frais de son manque de couverture par les systèmes d’informations et de communication, la Chine semble, quant elle, assez épargnée par les pandémies… l’outil sémantique intègre t’il le cantonais ou le mandarin… ? A vous de juger.
Le projet peut paraître séduisant. Il constitue un fantastique système de surveillance (un de plus, dirons les septiques) pour l’OMS. Même si l’information est bruitée (suite à un mauvais diagnostic, une information journalistique n’est pas une information scientifique) ou comporte des erreurs dans le couple d’attribution maladie / lieu, l’outil a misé sur la vélocité dans son aptitude à remonter de l’information que l’on souhaite la plus pertinente possible. Il est en perpétuelle amélioration. Sur Health Map, vous pouvez suivre jour après jour, tels des boutons de varicelles, des spots en relation avec votre agent infectieux favori s’illuminent sur la carte mondiale. Outre l’outil (une application de la fouille de texte, encore une) le site internet est très ergonomique et utile notamment pour sa section : « The Disease Daily« . Une critique possible : le continent africain fait les frais de son manque de couverture par les systèmes d’informations et de communication, la Chine semble, quant elle, assez épargnée par les pandémies… l’outil sémantique intègre t’il le cantonais ou le mandarin… ? A vous de juger.
Partenaires, collaborateurs & supports du projet : GOOGLE.ORG, NATIONAL INSTITUTES OF HEALTH RESEARCH / NATIONAL LIBRARY OF MEDICINECENTERS FOR DISEASE CONTROL AND PREVENTION, CANADIAN INSTITUTES OF HEALTH RESEARCHINTER, NATIONAL SOCIETY FOR INFECTIOUS DISEASES / PROMEDHEALTH AND HUMAN SERVICES, FLU.GOV, INTERNATIONAL SOCIETY FOR DISEASE SURVEILLANCE, INTERNATIONAL SOCIETY FOR TRAVEL MEDICINEGEOSENTINE, NEW ENGLAND JOURNAL OF MEDICINE, WILDLIFE CONSERVATION SOCIETY
 Il existe un endroit, un immeuble abritant un plateau technologique où les capacités de séquençage dépassent l’imaginable. Le pari est osé. Ce centre est confondu avec le BGI (Beijing Genomics Institute) alors qu’il se situe à un petit 2000 kms par route. Disons que Shenzhen, la quatrième ville du pays-continent en nombre d’habitants, se situant en bordure de Honk Hong, a un statut de zone économique spéciale. Depuis 1980 les entreprises étrangères sont autorisées à investir dans ce lieu propice… et c’est ainsi que cette localité a vu s’ouvrir le premier Mac Donald’s en Chine en 1990 (quelle chance !).
Il existe un endroit, un immeuble abritant un plateau technologique où les capacités de séquençage dépassent l’imaginable. Le pari est osé. Ce centre est confondu avec le BGI (Beijing Genomics Institute) alors qu’il se situe à un petit 2000 kms par route. Disons que Shenzhen, la quatrième ville du pays-continent en nombre d’habitants, se situant en bordure de Honk Hong, a un statut de zone économique spéciale. Depuis 1980 les entreprises étrangères sont autorisées à investir dans ce lieu propice… et c’est ainsi que cette localité a vu s’ouvrir le premier Mac Donald’s en Chine en 1990 (quelle chance !).La ville de Shenzhen est devenue après une montée en puissance depuis 2008, l’usine à séquençage du BGI et la plateforme mondiale possédant la plus grande capacité de séquençage à ce jour (crise mondiale oblige, il y a fort à parier que Shenzhen le reste pendant quelques années). Avec des débits de 8,5 Tbases / jours (plus de 1000 équivalents génomes humains par jour ! de quoi réaliser plus de 15 000 génomes humains complets), la plateforme du BGI à Shenzhen s’est distinguée avec :
- Son premier séquençage de novo du génome humain et de mammifère (le panda géant, séquencé sur la plateforme GA de Illumina) à l’aide de technologies de séquençage haut-débit à reads courts (publications de 2010 : Nature et Genome Reasearch)
- Son séquençage du premier homme pré-historique (à partir d’un prélèvement de cheveux conservé au muséum national du Danemark) (publication : Nature, 2010)
- Son séquençage du premier génome diploïde d’un individu asiatique dans le cadre du projet de Yan Huang (publication : Nature 2008)
- Sa construction d’une carte pan-génomique humaine, avec un ajout de 19 à 40 Mbases absentes de la séquence de référence humaine (publication : Nature Biotechnology 2010)
- Sa contribution à hauteur de 10% à l’information des séquences pour le projet HapMap humain
- Sa contribution à hauteur de 1% au Projet génome humain de référence (seul institut au monde en développement à contribuer au projet)
- Sa démonstration de la faisabilité du séquençage du microbiome du tube digestif humain, estimé à 150 fois plus grand que le génome humain (publication : Nature 2010)
- Son action clé dans le projet sino-britannique du projet de séquençage du génome de poulet
- Le BGI avec Shenzhen est le principal centre de séquençage dans le projet 1000 génomes, elle a été la première institution chinoise à séquencer le virus du SRAS, quelques heures seulement après le premier séquençage du virus par des Canadiens, et a été un acteur clé dans l’analyse de l’épidémie à E. coli O104:H4
Les projets 10 000 génomes microbiens, 1000 génomes eucaryotes sont souvent qualifiés de pharaoniques. Cependant avec cette quantité de machines, avec l’argent disponible pour le consommable soit plus de 1,5 milliards de USD sur 10 ans, avec de la main d’oeuvre qualifiée disponible et un « pipe-line » d’assemblage et d’analyse développé… ces deux projets devraient être achevés comme prévu (cette notion a cours en Chine).
Souvent les projets pleuvent, mais les financements un peu moins. Avec des débits (calculés selon les spécifications des fournisseurs de séquenceurs) de plusieurs génomes humains / jour, avec l’équivalent de plus de 100 millions d’USD d’investissements en unités de séquençages, il reste du temps machine à occuper.

Un virage économico-scientifico-politique a été amorcé par le gouvernement chinois. Ceci peut être résumé par l’équation suivante : investissement massif d’argent avec objectifs scientifiques à court et moyen terme, rentabilisation quasi- immédiate de l’investissement matériel en l’ouvrant à des prestations de service, assommer la concurrence en occupant le terrain des publications scientifiques et en proposant des prix de séquençage cassés (cf. publicité ci-dessus, source site web du BGI Europe) en ce qui concerne les prestations de service (Shenzhen, zone économique spéciale n’est pas une implantation géographique choisie au hasard… la génomique aux portes de Macao et de Honk-Hong).
Forts de cette mécanique bien huilée, les scientifiques chinois trustent les bonnes feuilles de Nature… investissement financier avec un fort impact bibliométrique. Le gouvernement français s’est inspiré des bonnes recettes chinoises : des investissements publics colossaux dans des sciences technophages, une collaboration réelle ou feinte des secteurs public et privé, un retour sur investissement rapide sous forme de publications. Après le grand emprunt, le gouvernement français soucieux de cumuler rayonnement scientifique international et relance de la croissance économique, a injecté quelques deniers en Equipex et Labex. La science comme moteur de croissance économique. Attention au retour sur investissement car, quand les bourses se contractent le créancier devient plus soucieux du rendement de ses deniers.

En conclusion, si le modèle chinois semble vertueux sur le plan du développement scientifique et technologique, il est basé avant tout sur un modèle économique où le dumping social, où le rendement bibliographique à court terme deviennent pierres angulaires de la techno-science. La technologie doit servir la science, l’inverse n’a pas de sens. La Chine a l’ambition de devenir une bibliothèque d’Alexandrie numérique avec son projet « library of digital life« . Après avoir conquis l’espace, les marchés mondiaux, après être devenu le créancier des Etats Unis, la Chine souhaite devenir la puissance scientifique (c’est surtout exact concernant les sciences de la vie) qui éclaire le monde.
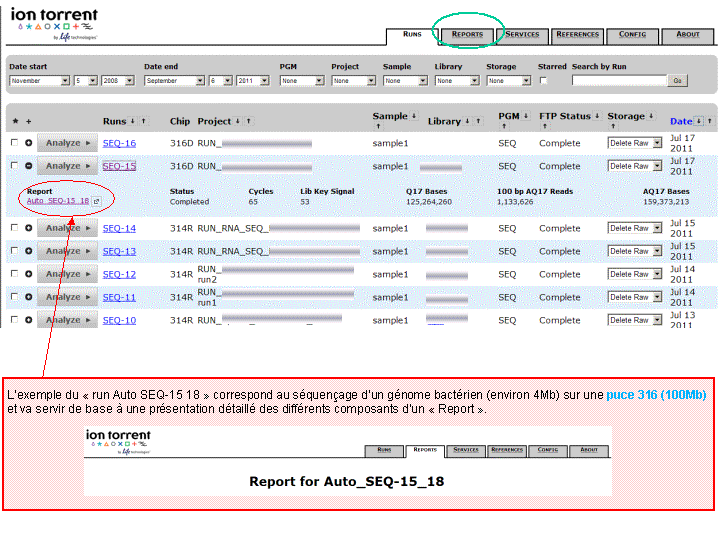
 Il s’agit d’un run sans valeur biologique qui a été réalisé dans le cadre d’une validation proposée par le fournisseur (Life) pour le « label CSPro ». Ce run consiste notamment, en un re-séquençage de E. coli DH10B.
Il s’agit d’un run sans valeur biologique qui a été réalisé dans le cadre d’une validation proposée par le fournisseur (Life) pour le « label CSPro ». Ce run consiste notamment, en un re-séquençage de E. coli DH10B.Ce type de données peut (vous) permettre d’évaluer la technologie (taux d’erreur, profondeur…) de séquençage haut-débit d’une part. D’autre part ces données peuvent servir afin d’évaluer les logiciels d’assemblage tels que ceux que nous possédons (DNastar, CLC genomic workbench, Partek…) pour des reads issus de PGM (Ion Torrent).
- Accès au jeu de données librairie DH10B au format sff (compressé)
- Accès à la référence, génome annoté de DH10B
- Accès au rapport de run au format pdf
- Accès au Library Sequence (FASTQ)
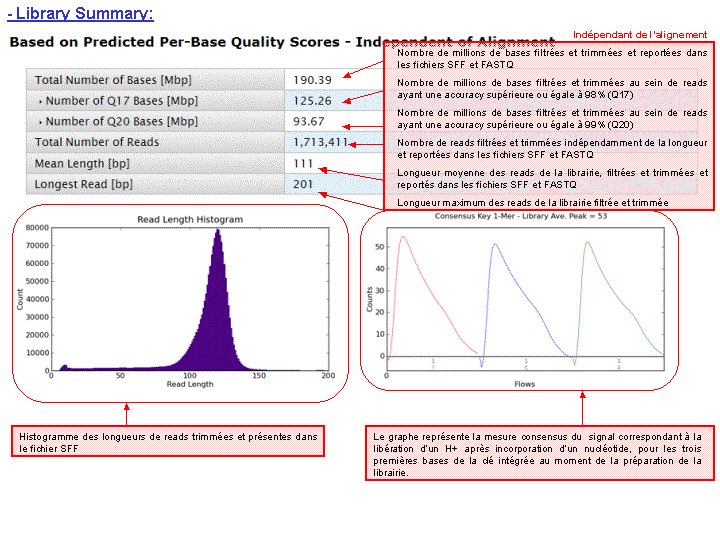
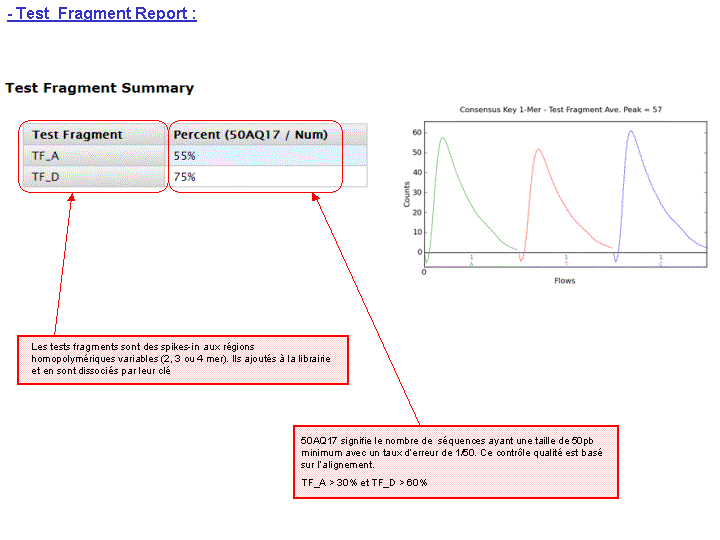
Vous trouverez ci-dessous une partie du rapport de run relative à la qualité des reads générés et alignés sur le génome de référence à l’aide de la suite Ion Torrent version 1.4.1

Ce run a été réalisé sur une puce 314, consommable fourni pour 10 Mbases de séquençage brut (ici nous dépassons les spécifications, 32.99 Mbases séquencées, même si le présent run est considéré comme assez moyen par rapport aux résultats précédemment obtenus). Malgré tout, il est possible de couvrir un petit génome à plus de 4X à des coûts imbattables (pour l’instant)!
 Le contenu scientifique a bien souvent besoin d’être traduit et la démarche du chercheur nécessite d’être expliquée (nous ne sommes pas très loin des notions d’éthique). La vulgarisation peut parfois être un outil permettant d’éveiller l’opinion qui, de ce fait peut s’en faire une, ou à rebrousse poil, elle peut être une méthode visant à la rassurer. Nous pouvons lire et relire les méthodes employées par Edward Bernays pour transformer le citoyen en consommateur.
Le contenu scientifique a bien souvent besoin d’être traduit et la démarche du chercheur nécessite d’être expliquée (nous ne sommes pas très loin des notions d’éthique). La vulgarisation peut parfois être un outil permettant d’éveiller l’opinion qui, de ce fait peut s’en faire une, ou à rebrousse poil, elle peut être une méthode visant à la rassurer. Nous pouvons lire et relire les méthodes employées par Edward Bernays pour transformer le citoyen en consommateur.
La biotechnologie alimente les peurs par ce qu’elle peut engendrer dans un laboratoire et qui échapperait au contrôle citoyen dès lors que l’invention devient produit, par exemple. Cet article est l’occasion d’écouter un exemple de vulgarisation scientifique : l’émission de Là-bas si j’y suis (excellente émission du service public, sur France Inter), du vendredi 15 décembre 2006, » Leçon de choses : Les OGM « .
Dans cette émission Christian Vélot explique avec un magnifique esprit de synthèse ce que sont les OGM, dans son Laboratoire de recherche en Génétique Moléculaire, à Orsay. Christian Vélot est un lanceur d’alerte, un exemple de libre chercheur, libre penseur qui a réussi à faire sortir la science de son laboratoire pour l’amener dans le champ du débat… une nécessité absolue surtout s’agissant des applications biotechnologiques. L’intervention de Christian Vélot, dans l’émission de Daniel Mermet est un modèle du genre, en effet bien que techniquement imparfaite, elle incite l’auditeur à prendre du recul et à aller se documenter sur le sujet en le dépassionnant, en évitant l’ornière des sempiternels poncifs. De la connaissance naît la curiosité qui enrichit l’argumentation, essence de toute opinion et l’accès à ces arguments est la voie vers la décision et donc vers… la démocratie.
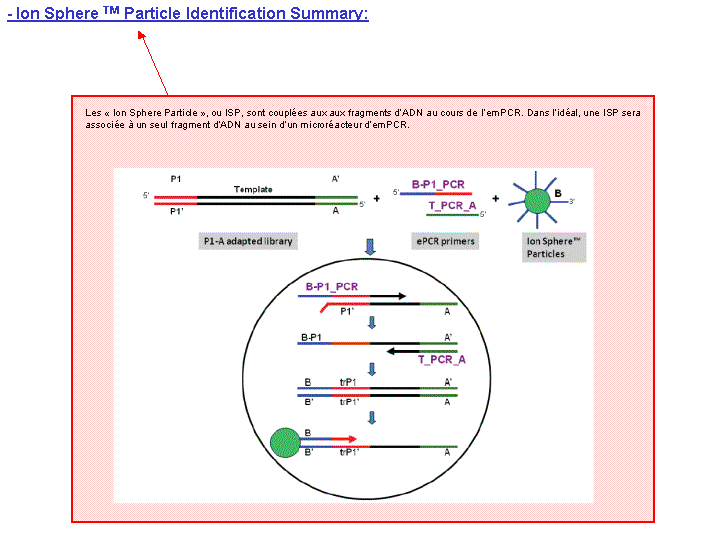
A l’issue d’un « run » de séquençage Ion Torrent (PGM), l’ensemble du signal brut (ionogramme) est converti en séquences et stocké au niveau du serveur. Pour chaque « run de re-séquençage», un alignement préliminaire est réalisé sur la base du génome de référence mentionné lors de l’initialisation du PGM. Cette information est reprise au travers d’un rapport qui comporte également un ensemble de paramètres, que l’on se propose de détailler ci-dessous :
(Cliquer pour agrandir) 
Le rapport se divise en 5 sections:

")

")
")





Le ppf (Portail du Plan Pluriformation) bioinformatique de Lille 1 organise le 20 septembre prochain sur le campus de Lille 1 une journée scientifique sur la fouille de texte pour la biologie (extraction d’information en génomique, inférence des interactions géniques, …).
Le programme et les détails pratiques sont disponibles sur la page http://www.lifl.fr/~touzet/PPF/fouilletexte11.html
Qui sommes nous?
Christophe Audebert [@]
 En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
Renaud Blervaque [@]
 Biologiste moléculaire, chargé d'études génomiques.
Biologiste moléculaire, chargé d'études génomiques.
Gaël Even [@]
 Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.
Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.


{kind=link}
{kind=link}
{kind=link}
{kind=link}