
En cancérologie, l’allogreffe de moelle osseuse s’inscrit dans un parcours thérapeutique notamment comme traitement de consolidation après une chimiothérapie. Aussitôt, les notions de rejet ou d’acceptation du greffon apparaissent et il devient indispensable que les systèmes HLA (Human Leucocyt Antigens, découvert en 1950) du donneur et du receveur soient les plus proches possibles.
Ce système immunogène, situé sur le bras court du chromosome 6 chez l’homme, est caractérisé par son polygénisme et son polymorphisme qui sont à l’origine d’une grande variabilité interindividuelle et en fait le déterminant principal du résultat de greffe. L’ensemble des gènes HLA sont subdivisés en trois régions du chromosome 6 qui contiennent chacune de nombreux gènes avec ou sans fonction immunologique. On distingue ainsi la région CMH de classe I, de classe II, et de classe III.
A ce jour, un rendu de typage est ciblé sur une portion génomique restreinte codant pour le HLA. Il s’agit de l’exon 2 et 3 des loci HLA-A, HLA-B et HLA-C (région I), l’exon 2 et 3 des loci HLA-DQ (DQ-A et DQ-B) et l’exon 2 pour HLA-DR (DRA et DRB1), où repose prés de 70% du polymorphisme. La région III ne renfermant pas de gènes intervenant dans la présentation antigénique.

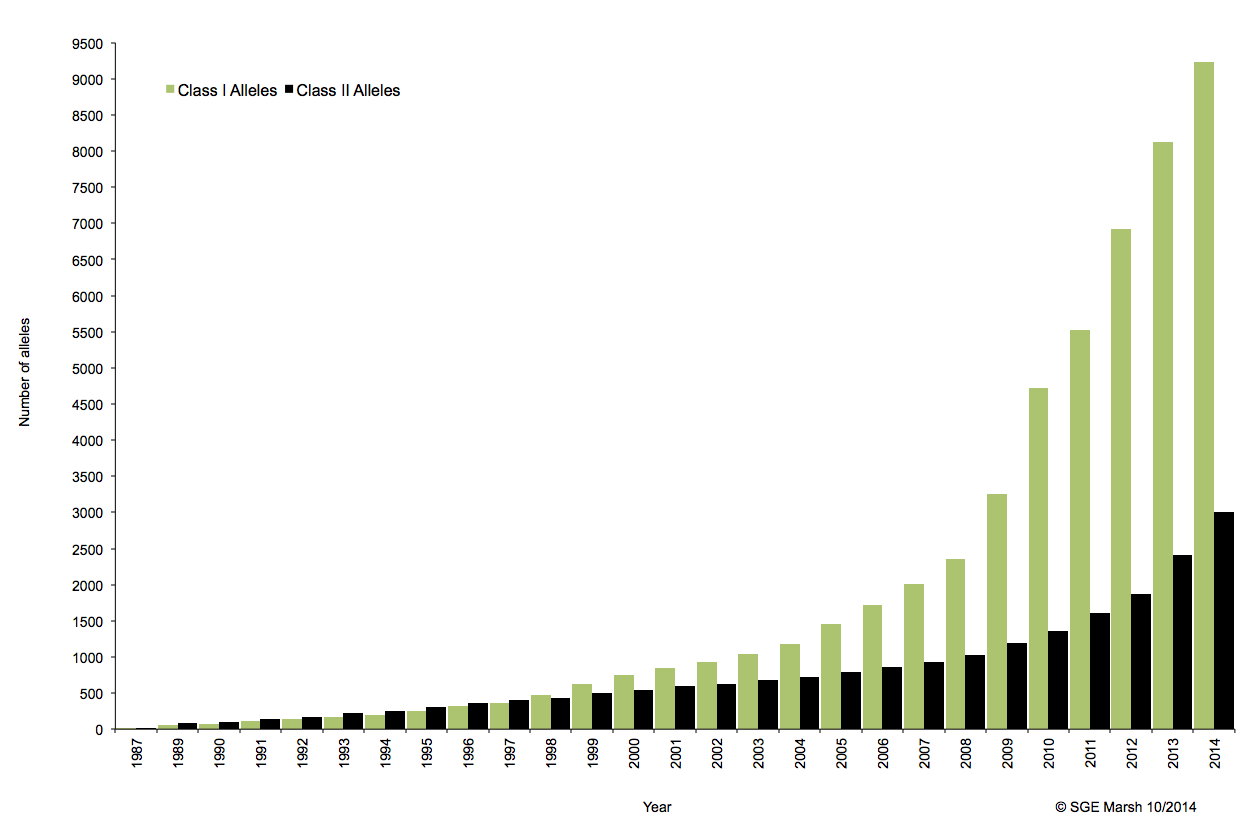
C’est ainsi que différentes approches de typages ont été développées et l’avènement de la technique de PCR au milieu des années 1980 a pallié aux limites de résolution de la sérologie employée jusqu’alors. D’un typage rendu au niveau générique (2 Digits), la « PCR-SSO » (Sequence Specific Oligonucleotide) et la « PCR-SSP » (Sequence Specific Primer) développées dans les années 1990 ont permis d’accéder à un résultat allélique (4 Digits). Cette avancée technologique s’est poursuivie la décennie suivante avec la « PCR-SBT » (Sequence Based Typing) ou séquençage « Sanger » puis plus récemment avec la PCR en temps réel (ex: linkage). Toutes ces techniques de biologie moléculaire ont permis de mettre en avant le polymorphisme et la grande diversité génétique du HLA. Chaque année, de nombreux allèles sont découverts, alimentant continuellement la banque de données de référence IMGT.

Associé à cette augmentation constante du nombre d’allèles typés, le nombre d’ambigüités croît et met progressivement en difficulté les technologies conventionnelles qui atteignent leurs limites. De plus, le pourcentage de réussite des allogreffes n’atteint environ que 50%. L’exploitation du reste de l’information génomique permettrait potentiellement d’améliorer cette performance par un typage plus affiné.
Le recours au séquençage nouvelle génération apparait donc inévitable. En plus de gérer les ambiguïtés par un séquençage allélique, le NGS permet de traiter simultanément de grandes quantités d’échantillons réduisant ainsi le coût unitaire, d’accéder à un niveau de résolution supérieur (4,6 ou 8 digits) tout en ayant la capacité de cibler des loci entier (Long Range PCR).
Ainsi, plusieurs stratégies existent avec leur solution technique adaptée à la préparation de la matrice d’ADN à séquencer:
– L’amplification ciblée des régions d’intérêt par PCR de fusion. Cette approche permets un gain de temps et une réduction des coûts en s’affranchissant des étapes de fragmentation, ligation, et autres purifications… .Par ailleurs elle n’est pas la mieux adapté dans le cas d’une couverture de séquençage de l’ensemble de la région génomique HLA.
– L’amplification par « Long Range PCR » permet une couverture complète des différents loci étudiés. Les fragments de plusieurs Kb subissent alors une fragmentation, une ligation des adaptateurs et indexation. Cette approche permet d’accéder à davantage d’informations (régions exoniques et introniques).
– La capture de séquences par hybridation. Même si cette solution est bien caractérisée elle n’est pas si efficace en terme de capture avec une disparité selon la taille des fragments.
– Le séquençage de génome entier ou d’exome. Cette approche est la moins biaisée et couvre tous les gènes du système HLA. Paradoxalement, l’analyse nécessite beaucoup trop de ressources pour une utilisation en routine et ne permets pas de traiter autant d’échantillons simultanément.
Plusieurs sociétés commerciales proposent des solutions clé en main depuis la préparation des échantillons (avec l’option « Long Range PCR » qui semble la plus plébiscité) jusqu’à l’analyse de résultats via leur logiciel dédié. Certaines sont en cours de validation de méthode pendant que d’autres tentent d’inonder le marché. Parmi elles, Gendx, Omixon, Illumina, One lambda, Life technologies, Immucor, etc…

L’exploitation des capacités et caractéristiques des solutions de séquençage à haut-débit permettrait d’affiner considérablement le typage HLA. Ainsi le décryptage de l’ensemble des régions codantes et non-codantes du génome d’intérêt représente un enjeu important dans la réussite des greffes. Par ailleurs, cette approche nécessitera une mise à jour considérable des banques de données (IMGT) avec une validation de nombreux nouveaux allèles.
renaud blervaque
Partager cet article



Qui sommes nous?
Christophe Audebert [@]
 En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
Renaud Blervaque [@]
 Biologiste moléculaire, chargé d'études génomiques.
Biologiste moléculaire, chargé d'études génomiques.
Gaël Even [@]
 Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.
Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.


{kind=link}
{kind=link}
{kind=link}