
![]() Une jeune start-up est née en mai 2012 : cette société issue du CNRS est porteuse d’une innovation dans le secteur du séquençage haut-débit. Enfin, une alternative française aux anglosaxons qui sont présents sur le marché depuis une dizaine d’année ! Maintenant… espérons que ce nouveau né n’arrive pas trop tard sur un marché animé par des fournisseurs de séquenceurs de 2ème génération (un marché mature) et d’autres fournissant des solutions de 3ème génération, riches de promesses.
Une jeune start-up est née en mai 2012 : cette société issue du CNRS est porteuse d’une innovation dans le secteur du séquençage haut-débit. Enfin, une alternative française aux anglosaxons qui sont présents sur le marché depuis une dizaine d’année ! Maintenant… espérons que ce nouveau né n’arrive pas trop tard sur un marché animé par des fournisseurs de séquenceurs de 2ème génération (un marché mature) et d’autres fournissant des solutions de 3ème génération, riches de promesses.
PicoSeq derrière ce nom emprunt d’humilité se cache une technologie de séquençage des plus ingénieuses : en effet, SIMDEQ™ (SIngle-molecule Magnetic DEtection and Quantification) la technologie de PicoSeq utilise une approche biophysique pour extraire des informations à partir de la séquence d’ADN ou d’ARN.
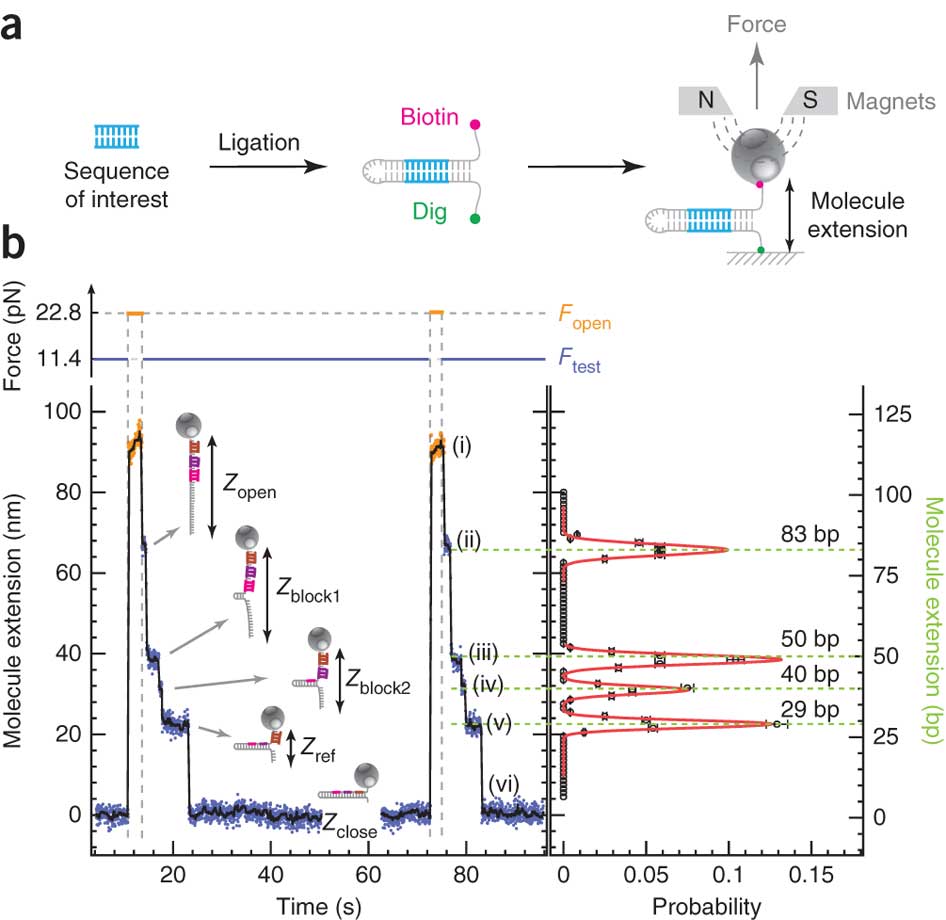
En s’appuyant sur cette représentation schématique tirée de Ding et al. (Nature Methods, 2012), on y voit un peu plus clair. Des fragments d’ADN ou d’ARN que l’on souhaite analyser servent de matrice pour la réalisation d’une librairie en «épingle à cheveux». Pour chaque épingle à cheveux, un côté d’un brin d’acide nucléique est attaché sur une surface solide plane et l’autre à une bille magnétique. En plaçant les billes dans un champ magnétique, modulant celui-ci de manière cyclique, les épingles à cheveux peuvent être auto-hybridées ou non (zip ou unzip). Ce processus peut être effectué des milliers de fois sans endommager les molécules constitutives de la librairie. La position de chaque bille est suivie à très haute précision permettant de voir ce processus d’ouverture et de fermeture en temps réel: nous avons donc là un signal brut permettant, en fonction de la force appliquée pour ouvrir totalement l’épingle à cheveu et des séquences d’oligonucléotides séquentiellement introduites dans le système de modifier la distance bille-support et de jouer sur le temps nécessaire où la force s’applique pour ouvrir l’épingle à cheveu…
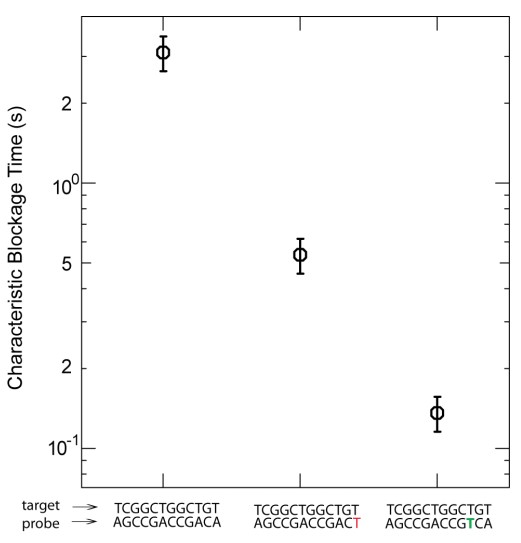
La figure ci-dessus (présente dans les données supplémentaires de l’article sus-cité) permet d’appréhender le potentiel de discrimination de la méthode… où le temps de blocage est fonction du nombre de mésappariements et de la position de ces mésappariements…
Finalement si l’aspect technique est intéressant puisqu’en rupture avec les méthodes proposées par PacBio certainement un peu moins avec le système proposé par Oxford Nanopore Technologies, si la perspective annoncée par PicoSeq est réellement séduisante: l’accès modifications épigénétiques de l’ADN, la question centrale est de savoir si le pas de la commercialisation (dans des conditions propices au succès) d’un tel outil, sera franchi.
Un article d’ Atlantico de septembre 2015, titré : les trois raisons pour lesquelles la France est incapable de rivaliser avec les géants américains de l’analyse ADN, est assez éclairant pour imaginer comment la concrétisation d’une preuve de concept peut être un chemin ubuescokafkaïen. Pour illustrer cela les propos de Gordon Hamilton, le directeur de la startup PicoSeq qui s’inquiète sur les entraves « typically french » peuvent faire office de témoignage. Ce dernier s’inquiète : « La qualité de la recherche scientifique (en France) est incroyable, l’une des meilleures » « le seul souci, c’est que l’on a beaucoup de difficultés ici à transformer ces recherches en vrai business » pour finir par citer en exemple les lenteurs administratives spécificités latines : « nous avons mis presque deux ans pour négocier les licences nécessaires aux brevets de Picoseq. Le même processus en Californie prend entre deux semaines et deux mois. Sur un marché aussi rapide que celui-ci, deux ans c’est très long. Tout change vite, c’est donc impossible pour nous d’être de sérieux concurrents de ces sociétés américaines qui ont toujours un temps d’avance ».
c.audebert
Partager cet article



2 Responses to Picoseq : le « séquençage » made in France
Laisser un commentaire
Qui sommes nous?
Christophe Audebert [@]
 En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
Renaud Blervaque [@]
 Biologiste moléculaire, chargé d'études génomiques.
Biologiste moléculaire, chargé d'études génomiques.
Gaël Even [@]
 Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.
Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.


Alors ? Où en est PicoSeq, maintenant Depixus ?
Je ne parviens pas à contacter quelqu’un.
Y-a-t-il une communauté d’utilisateurs (genre MinIon) ?
Je suis près à participer:
– en réalisant mes analyses dans le contexte agro-écologie
– en écrivant du logiciel
– …
Navrant que le CEO dise (en substance ou clairement;
je serais preneur de l’original):
« Il nous est impossible d’y arriver »
Picoseq est à l’eau ? Comme un vieux parti politique on en change le nom… Depixus :
https://depixus.com/ en effet.
Au passage, désolé pour le délai de notre réponse votre message était noyé dans des brouettes de spams.
Pas plus de nouvelle que vous si ce n’est ceci :
http://www.agoranov.com/concours-mondial-dinnovation-decouvrez-2-incubes-laureats-de-3e-phase/
J’aime assez la description en « mode » ayez confiance! :
« Depixus (anciennement PicoSeq) est une spin-out en biotechnologie issue du Laboratoire de Physique Statistique de l’Ecole Normale Supérieure. L’entreprise développe des technologies pour réaliser l’extraction rapide, précise et peu coûteuse de l’information génétique et épigénétique à partir de molécules uniques d’ADN et de l’ARN. La validation des technologies de Depixus est à un stade avancé et le développement commercial est en cours. La société est soutenue par un groupe d’investisseurs expérimentés, dont plusieurs sont des vétérans de l’industrie du séquençage. »