
Le choix d’une méthode analytique confortable, fiable, adaptée au profil de données (avec un peu ou beaucoup d’erreurs liées à la technologie de séquençage utilisée), à votre degré d’expertise, est souvent un casse-tête et un dédale qui occupent certains partenaires d’un projet nécessitant le recours à une analyse métagénomique ciblée. D’autres encore décident de ne pas décider, de ne pas se lancer dans le labyrinthe et votent ainsi pour une solution tout-terrain, sorte de martingale génomique, proposée par des prestataires de services.
Cet article de Plos One : Assessment of Common and Emerging Bioinformatics Pipelines for Targeted Metagenomics tente – ayant un conflit d’intérêt majeur, je n’en ferai pas la critique – d’identifier les grandes approches algorithmiques disponibles. Quels sont les paramètres influençant la qualité des résultats ?
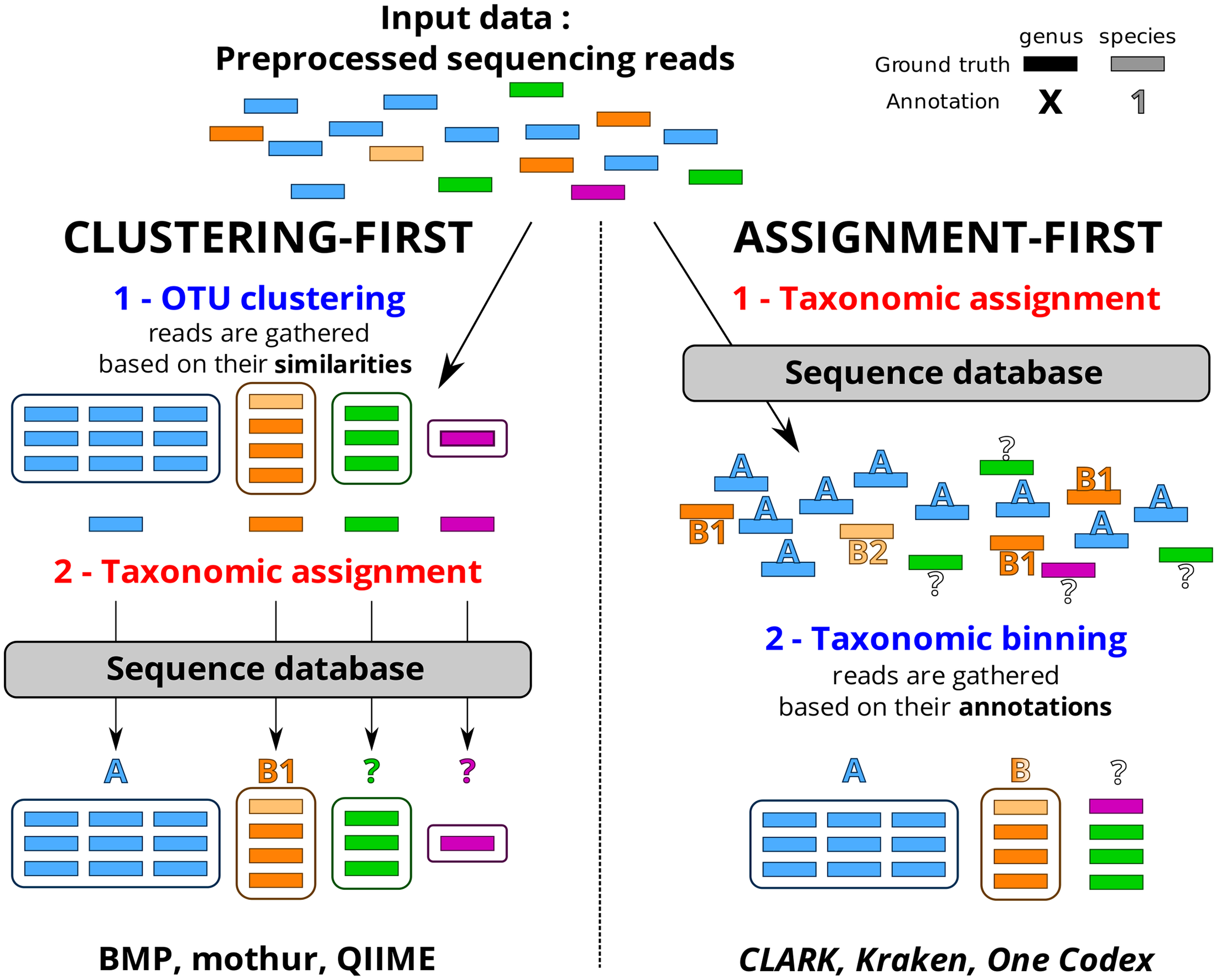
Ce travail a permis de fournir un canevas généralisable permettant d’évaluer un pipeline analytique et d’observer dans quelle mesure ce dernier influe sur la qualité des résultats. Concernant le protocole mis en place ainsi que d’autres ressources nécessaires (jeu de données simulées, réelles etc.) vous pourrez consulter la page dédiée à ce travail sur le site de PEGASE-biosciences.
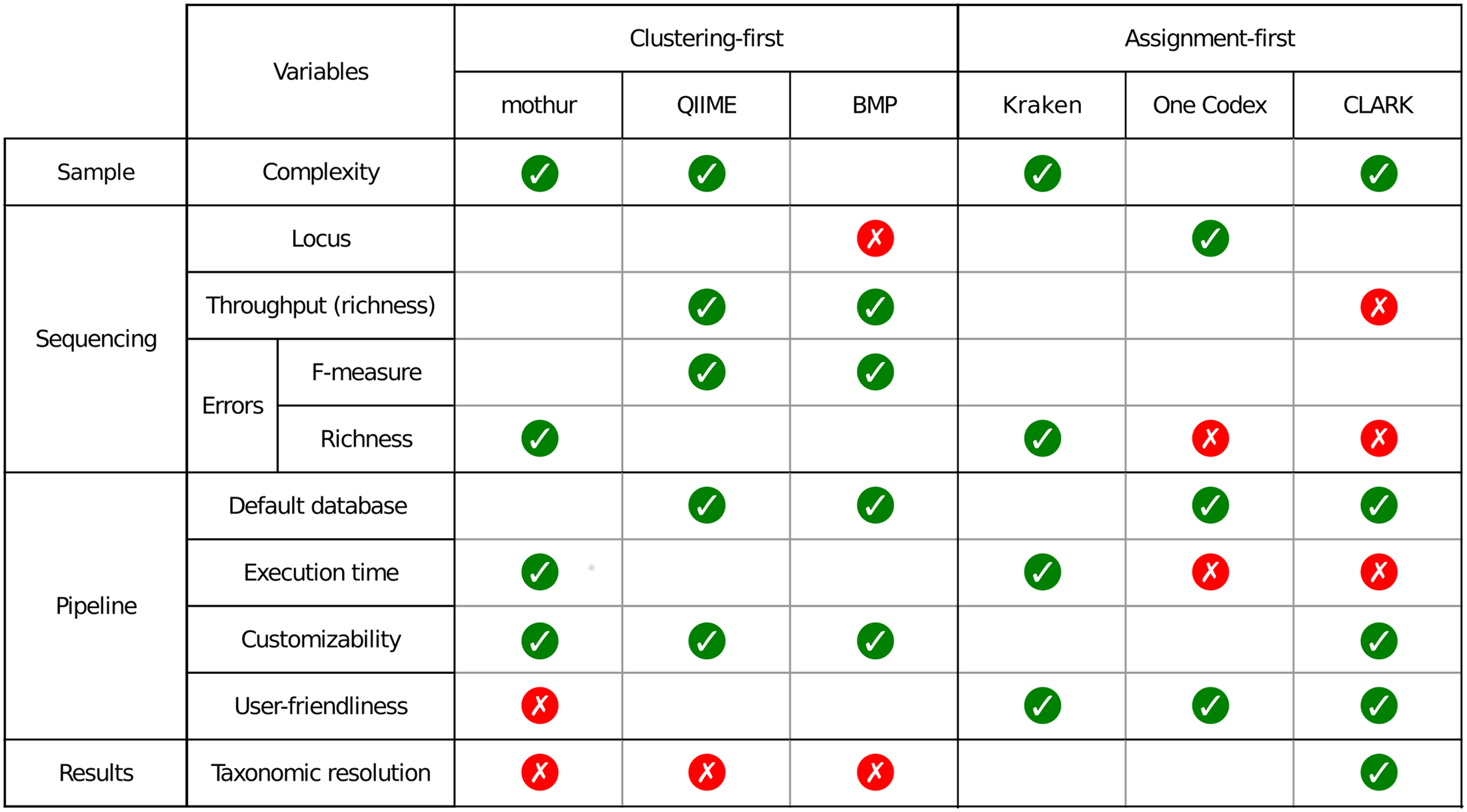
Un petit tableau synoptique permet de synthétiser les caractéristiques principales des pipelines évalués dans l’article.
c.audebert
Partager cet article



Qui sommes nous?
Christophe Audebert [@]
 En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
En charge de la plateforme génomique
du département recherche et développement
de la société Gènes Diffusion .
Renaud Blervaque [@]
 Biologiste moléculaire, chargé d'études génomiques.
Biologiste moléculaire, chargé d'études génomiques.
Gaël Even [@]
 Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.
Responsable bioinformatique au sein
du département recherche et développement de la société Gènes Diffusion.

